geom_jitter() 개요
geom_point()에 대한 내용은 아래 포스팅을 참조해주시기 바랍니다!
geom_point 함수, 연속형 변수 시각화
geom_point() 개요 geom_point() 함수는 R 프로그래밍 언어의 ggplot2 패키지에서 사용되는 함수로, 산점도(Scatter plot)를 생성하는 데에 활용됩니다. 이 함수는 ggplot2 패키지의 일부이며, 데이터 시각화 작
jacey312.com
이번 포스팅에서는 geom_jitter() 함수에 대해 자세히 살펴본 후 geom_point() 함수와의 차이점을 살펴보도록 하겠습니다.
geom_jitter() 함수의 장점은 geom_point() 함수와 달리 데이터를 한줄로 겹치게 나타내지 않고 데이터들이 서로 겹치지 않도록 흩뿌려서 시각화합니다. 이러한 점 때문에, geom_jitter() 함수는 막대 그래프나 상자 그림 등으로는 표현하기 어려운 데이터의 분산을 시각적으로 나타낼 수 있습니다. 특히, 범주형 변수와 연속형 변수 간의 관계를 시각화할 때 유용합니다. 그리고 데이터가 서로 겹치는 부분이 많을 경우에도 각 점의 밀도를 시각적으로 표현할 수 있어 좋습니다.
하지만 geom_jitter() 함수의 단점은 데이터가 많이 겹쳤을 때 점들이 서로 가려져 해석이 어려워질 수 있습니다. 이는 데이터 양이 많아 서로 겹치는 데이터 양이 많은 경우에 특히 문제가 될 수 있습니다. 데이터가 밀집되어 있을 때, 점을 무작위로 흩뿌리면서 원래 데이터의 정확성을 상실할 수 있습니다. 또한, point가 무작위로 흩뿌려지면서 데이터의 분포가 왜곡될 수 있으며, 특히 데이터셋이 작거나 특정한 패턴을 나타낼 때, 왜곡이 발생할 수 있습니다.
geom_jitter()와 geom_point()의 비교
상기 서술한 내용과 같이 geom_jitter()는 geom_point()와 달리 데이터가 서로 겹칠 경우에 점들을 흩뿌려주어 서로 겹치지 않도록 하는 점에 대해 비교하는 코드를 작성하도록 하겠습니다. 아래 예시에서는 reshape 패키지의 tips 데이터를 응용하였습니다. tips 데이터셋 중 day, tip 데이터를 각각 X축과 Y축에 적용하여 산점도를 나타내도록 하였습니다.
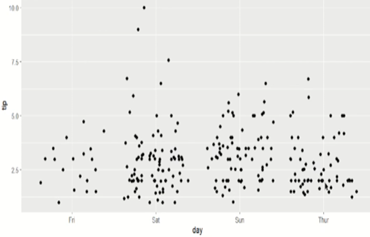
아래 그림에서 살펴보는 것과 같이, geom_point() 함수를 적용한 그래프에서는 각 day별로 point가 일렬로 나열되는 형상을 보이고 있어 특정 위치에 point가 어느 정도 겹쳐져 있는지를 확인하기 어렵습니다.
반면, geom_jitter() 함수를 적용한 그래프에서는 각 day별로 point가 서로 겹치지 않도록 흩뿌려지게 그려져 있어 point가 어느 정도 겹쳐지는 지, 어떤 위치에 point가 집중되어 있는지를 사용자가 눈으로 쉽게 인지할 수 있습니다.
library(reshape2)
# geom_point() 활용
ggplot(tips, aes(day,tip))+geom_point()
# geom_jitter() 활용
ggplot(tips, aes(day,tip))+geom_jitter()
geom_point()에서도 겹친 비중 확인하는 방법 - size 인수 & sclae_size_area()
geom_point() 함수는 데이터가 겹쳐지게 표시된 경우에 육안으로 쉽게 식별하기가 어렵다는 단점을 가지고 있습니다. 이 때문에 geom_jitter() 함수를 사용하는 경우가 많은데요, geom_jitter() 함수를 사용하지 않고도 geom_point() 함수로도 데이터가 겹쳐져 있는 정도를 확인할 수 있는 방법이 있습니다.
앞선 geom_point() 함수 관련 포스팅에서는 point의 투명도를 alpha 인수를 사용하여 조정하는 방법을 설명드렸는데요, 본 포스팅에서는 이 외에도 "size = density" 인수와 scale_size_area() 함수를 추가 적용하는 방법을 설명드리겠습니다.
size = density 인수는 ggplot2의 내부 계산값으로 데이터의 밀도를 나타내어 주고, scale_size_area() 함수는 size 인수의 범위를 조절하여 관측값에 따라 데이터 point의 크기 차이를 더 확실하게 나타냅니다. 즉, 관측값이 작은 부분의 point는 보다 약하게 표시하여 사용자가 point의 겹친 정도를 더욱 확실하게 인지할 수 있도록 합니다.
# scale_size_area() 추가 전
ggplot(small, aeS(eruptions, waiting))+ geom_point(aes(size=density), alpha=1/3)
# scale_size_area() 추가 후
ggplot(small, aeS(eruptions, waiting))+ geom_point(aes(size=density), alpha=1/3)+ scale_size_area()

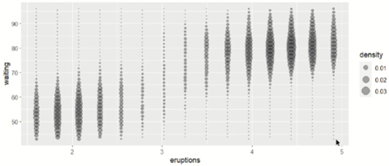
위의 그림을 보시면, scale_size_area() 함수를 추가 적용한 경우가 그렇지 않은 경우보다 point 비중이 낮은 부분에서 point가 표시되는 정도가 약할 것을 확인할 수 있습니다.
'Data Science' 카테고리의 다른 글
| 범주형 변수 비중 분석, geom_mosaic() (0) | 2023.12.31 |
|---|---|
| geom_histogram() 살펴보기 (0) | 2023.12.30 |
| 대표적인 범주형 plot, geom_bar() (0) | 2023.12.30 |
| 산점도와 함께 쓰는 geom_smooth() (0) | 2023.12.30 |
| 통계값 시각화 방법 (0) | 2023.12.30 |



